How to structure a long list of examples with SpecFlow?
Last time, we started a community challenge to suggest improvements to a badly worded Given-When-Then feature file, specifically addressing the problem of setting up something that’s not supposed to exist. This article contains an analysis of the responses, some tips on a more general approach to solving similar problems, and a new challenge for this week.
I’ve outlined some of the most common problems with describing something that doesn’t exist in the original challenge, so I will not repeat them here – check the linked post for a refresher.
We received lots of excellent responses to the first challenge, from people in sixteen different countries. Alister Scott even wrote a wonderful blog post about his proposal.
Here is the challenge
Describe what exists instead
Although the problems with describing something that doesn’t exist sound like technical challenges that are purely related to testing, they are often just symptoms of an unexplored model. It’s possible to solve or avoid most of them by exploring the model differently, and ensuring shared understanding between team members and stakeholders. Concrete examples are a great way to do that, and many solutions tried to make things more concrete by introducing different properties of users, or talking about users before they register in a different way.
For example, several suggestions involved introducing a specific qualifier, such as an “unregistered user”. This helps to differentiate between two different types of entities: one that exists before registration, and another that exists after. Similarly, some solutions tried to move away from an ambiguous user identifiers, such as “john”, to more concrete data available even users aren’t registered. For example, it’s possible to consider user emails even before they sign up to our system. The following suggestion, which also came in anonymously, illustrates this nicely:
Given user john@doe.com tries to create an account
When there is already an account for john@doe.com
Then registration is not possibleAll these attempts are going in the right direction, but they are still just workarounds for a problem and they aren’t solving it fully. On a conceptual level, a great way to approach similar problems is another anonymous suggestion, “Describe the state of the system without the value”. Instead of trying to describe something that is not supposed to exist, we can describe what else exists instead.
There are two ways of approaching this suggestion practically. The first, suggested by Mathieu Roseboom, is to look outside the system. Mathieu wrote “I’d emphasize that John is a person, and not a user.” Rather than talking about unregistered users that do not exist, let’s talk about people that do exist. The suggestions that tried to use emails to describe unregistered users lean in that direction, without fully benefiting from it. Thinking about person that exists outside of our system might leads us to discover about some other attributes, which could be important for the current feature.
The second way to specify something that exists instead of talking about vague non-existing entities is to describe all the other registered users. For example, one response suggested splitting the problem into two cases:
Given list of users is empty
...
Given a "normal" databaseAnother reader suggested setting up a separate feature file, that just creates the relevant users, and then technically ensuring that all other feature file tests run after it.
Feature: Setup users
Scenario: Register users
The following users are registered:
| name | email |
| Rick | rick@mail.com |David Wardlaw suggested starting the scenario with:
Given the following user is already registered
| First Name | Last Name | Email Address |
| John | Smith | js@bob.com |
And a new user wants to register with a first name of These three ideas illustrate different levels of visibility that feature files could offer. In the first option, readers will need to know what the “normal” database contains, but the solution is quite easy to reuse across different scenarios. On the other hand, if someone modifies the “normal” database for some unrelated reason, tests might start to break unexpectedly.
The second solution optimises performance because it inserts records only once, and provides better visibility to readers about the assumed state. The downside of this idea is that it imposes a very specific order for executing tests. This feature file must run before everything else, otherwise things start weirdly misbehaving. I usually try to avoid imposing a specific order of test executions, since then we can’t just run a single test when needed. This approach also suffers from implied shared state. If someone updates that central setup file for some unrelated test case, our tests may magically start to fail.
The third suggestion provides full visibility to a reader, and it does not impose any shared state that could cause problems later when things change. This approach might get a bit wordy if we need to set up a lot of users, but there are ways around that as well.
The key problem the first and second solution are trying to solve is the complexity and performance of working with a real database. Databases are slow and difficult to control compared to simple in-memory objects, so tests involving a real database often have to compensate for those downsides somehow. Between the three ideas, I would go with the third one unless there is some very specific performance constraint we want to solve. I promise to come back to this next week, but since we’re not solving database performance in this challenge, let’s just postpone that discussion.
So which approach should we choose? For that, I’d like to explore this problem on a more conceptual level, and explain several techniques which you can use with other similar situations.
Ask an extreme question
In order to reason about the existence of an item (such as a user or a product), we first need to answer a key probing question: where? Where should that item exist or not exist? Defining existence is, at core, reasoning about the state of system data. Figuring where the data resides is critical for three reasons:
- To resolve the chicken-and-egg issue of describing something before it exists, since we can talk about an item that simultaneously exists in one context, but not in another.
- To clarify the underlying business model, exposing previously hidden domain concepts. This will help us get a better shared understanding about their constraints.
- To create fast, reliable and resilient test automation, since identifying new domain concepts makes it possible to introduce additional control points. That’s how we can avoid premature performance optimisation, and having to deal with a real database.
Team members closer to implementation work, such as developers or testers, often think about entities as system data. They will intuitively understand that an entity always exists in a specific location, but they might not be able to share their assumptions about this easily with other team members. People not used to working with system state, such as business representatives, might struggle with that idea. They tend to think about existence in a more absolute way. A helpful probing technique to start the conversation about this concept is to ask an extreme question.
- What does it mean for a user not to exist? Were they not born yet?
- What does it mean for a product not to exist? Was it not manufactured? Was it not even designed yet?
These questions might sounds silly, but try them out and you’ll quickly see their value as conversation starters. Extreme questions often result with a hard “No”, and get people to start thinking about multiple contexts, a timeline or a scale. You will start identifying where an entity exists directly before it appears in your context, and what related information you can actually reason about at that point. Mathieu Roseboom’s suggestion to talk about a “person” is one potential outcome of such discussions.
The first set of answers to an extreme question is usually an overly generic statement. For example, the user might exist as a living person, but they don’t yet exist in “the system” or in “the database”. That’s a good starting point for the discussion, since we can now consider what’s known about an entity in different contexts. We can explore the domain much more easily.
Provide a meaningful domain name
A non-registered user likely exists as a living person, so we can talk about their personal name. They do not yet have a username in our system, so we can’t talk about it yet. They likely have an email, which is why so many responses to the challenge focused on that attribute. They might also have a preferred username in mind, which has nothing to do with them existing or not existing in our system. The When part can then become clearer:
When John Michaels attempts to register with the preferred username "john"A good technique to continue the discussion about something generic such as “system” or “database” is to provide a meaningful domain name. In the Domain-Driven-Design terminology, domain representations of entity stores are called Repositories. When developers hear the word “repository”, they often think about a common technical pattern that involves specific technical operations. Ignore that for the moment – that’s implementation detail. A repository is a meaningful first-order domain concept that encapsulates storing and retrieving data. Tell the rest of the team to imagine it as a box where you keep the users. If they can’t get over that, then think of a different name. I’ll keep using “repository” in this post.
Instead of a user existing or not existing in an absolute sense, we can potentially talk about the repository:
Given John does not exist in the user repositoryEven better, let’s make the user repository the subject of the sentence. The repository exists regardless of the users:
Given a user repository that does not include a user called JohnThe real precondition here is that a user repository exists, with some specific constraints about its contents. There’s no more chicken-and-egg issue. We identified an important first-order domain concept that we can reason about, regardless of a specific user.
Instead of just saying “does not include a user”, which is still a bit vague, we can now start capturing the constraints of the user repository in a more specific way, using an approach very similar to what David Wardlaw suggested. Here’s how I’d start writing it:
Given a user repository with the following users
| username | personal name |
| mike | Mike Smith |
| steve123 | Steve James |
When John Michaels attempts to register with the username "john"
Then the user repository should contain the following users:
| username | personal name |
| mike | Mike Smith |
| steve123 | Steve James |
| john | John Michaels |Add counter-examples
We now have a simple but concrete example. We’re not done yet, this is still just a good conversation starter. A good technique to continue the discussion is Simple-Counter-Key:
- Add a few more simple examples to show a range of potential outcomes, and discuss them.
- Try to provide counterexamples that disprove some of the proposed rules, and could lead to a different outcomes. This often helps to identify additional attributes, and a different structure for the Given section of the scenario.
- After you have a good structure, start listing important boundaries that illustrate the key examples.
The first step is to add at least one simple example, which could lead to a different outcome:
When Steve James attempts to register with the username "steve123"The outcome in this case might be obvious to everyone, but vary the data a bit. What happens if another “Steve James” attempts to register with the username “steveo”?
This can lead to an interesting conversation around the meaning of “uniqueness” and “existence”. Is the purpose of this feature to prevent the same person from creating multiple accounts in the system? If so, we should probably stop Steve from registering again, even with a different username. But if two different people called Steve James try to register, we should not prevent them. We need some other way of determining uniqueness, and personal names are obviously not good enough. Still, we might care about personal names in this scenario to ensure that we’re capturing them correctly in the repository. Are there any other attributes of a person that we should care about? This brings us back to the emails, suggested by several readers responding to the challenge. But how do we know that emails are the right thing to capture?
We can now start discussing the meaning of “unique” as relating to the person, and if emails are the right way to approach it. Some systems need to be lax about this, so they might let people register even with the same email. For example, a multi-tenant cloud app might want to allow opening sub-accounts with the same admin email to provide centralised billing. Those users will genuinely be different people, sharing a common email inbox. Many online systems today want to prevent abuse by validating emails, so they insist that every user has a unique email. Some systems need to be more strict, and they might enforce a unique mobile phone number. For government or banking purposes, even that’s not enough, and we might want to enforce unique date of birth, social security number, passport number or some other government-issued identifier. Different contexts will have different rules around this. Exposing those rules often leads to much better shared understanding, and also points to the attributes which should be captured for the key examples.
Discussing simple examples and counterexamples allows us to probe further into the model. What does it actually mean for a user to exist in our context? Does that mean the user repository has a record matching the specified email, or proposed username, or something else? How do we know that two users are not the same person? To keep things simple, let’s limit our case to just checking that the emails are different. We’ll say that a user exists in the system even if the proposed username is not taken, but we have a different username matching the same email. The simple scenario now evolves to capture the email as well:
Scenario: Users with a unique email should register successfully
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
When John Michaels attempts to register with the username "john" and email "johnm@gmail.com"
Then the user repository should contain the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
| john | John Michaels | johnm@gmail.com |We could add three or four more examples checking for duplicated emails and usernames in the same way, but this will very quickly become difficult to read.
If you’ve not yet read Alister Scott’s blog post about this challenge, now would be a good time to do it. He argues against misusing Given-When-Then to capture similar examples with small variances over and over again, suggesting that tables would be a better match for this case.
Tables are indeed a much better way of capturing related examples, but they can sometimes make it difficult to understand the purpose of a specific example from the group. Alister solves this nicely by pointing out differences between examples in an additional field, called Result. This field contains the explanation why a case failed, and what should have happened instead. For example, one of the results in his blog post is “Registration Unsuccessful – Reset password page displayed with email prefilled”. This points to another interesting thing we might want to check. Knowing that registration failed may not be enough – we need to know that it failed for the right reasons.
Extract scenario outlines
I agree with Alister that misusing Given-When-Then to copy and paste examples is a waste of time (and screen space). Tables are a good solution, and most Given-When-Then tools support listing tables of examples with scenario outlines. Scenario outlines use placeholders marked with <> inside a Given-When-Then scenario, followed by a table of examples with placeholder values. Here is how we could show two failure examples in the same structure:
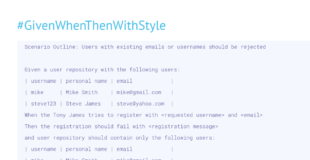
Scenario Outline: Users with existing emails or usernames should be rejected
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
When the Tony James tries to register with and
Then the registration should fail with
and user repository should contain only the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
Examples:
| requested username | email | registration message |
| steve123 | steve2@yahoo.com | Username taken |
| steve456 | steve@yahoo.com | Email already registered |Note that the When and Then statements contain placeholders relating to the table of examples, which is shown at the bottom.
Evolving Alister’s “result” idea, the registration message helps to explain what’s going on, but it’s also an important domain concept. Now that we identified it, we can talk about what that should contain. For a closely controlled system, we might want to immediately remind an existing user about his username, so he can sign in easily instead of registering or calling support staff. For an open public system, we might want to go in the other direction and mask the fact that an email is registered, and prevent potential malicious actors from inspecting accounts by trying to sign up.
Showing a comment in the table of examples is quite a common trick to explain the purpose of individual examples. Some people prefer to use the first column for that. I tend to use the first column if it’s a generic comment or name of the test, and does not play any role in the testable outputs. If we actually want to check it against some system output (in this case the registration message), I prefer to list inputs on the left and outputs on the right side of the table.
Probe for boundaries
The technique I mentioned earlier is Simple-Counter-Boundary. We still need to do the third step. So far we identified a few simple examples and some counter-examples. That’s a great start because it gives us the structure for discovering boundaries. Inspect each individual property in the Given section and probe with further examples.
What if someone tries to register with the proposed username “Steve123”? How about the email “Steve@Yahoo.com”? An email written in a different case is still the same, so the registration should probably fail. Some systems (notably Amazon AWS Cognito) by default do not enforce case-sensitive username checks, so two people could register with just a small difference in spelling. This is a support and maintenance nightmare, so let’s make sure we prevent it.
The nice thing about a scenario outline is that it’s very easy to add more examples. We can just append the following two cases to the table:
| Steve123 | steve2@yahoo.com | Username taken |
| steve456 | Steve@Yahoo.com | Email already registered |If we really want to avoid support problems with accounts that are too similar, perhaps we should also prevent people from registering usernames that only differ from existing accounts in interpunction symbols.
| steve.456 | Steve3@Yahoo.com | Username taken |
| steve_456 | Steve3@Yahoo.com | Username taken |Discussing boundaries often leads to more examples, and identifying hidden domain rules. And again, some systems will have different rules. Expose an example, discuss it, then decide if you want to keep it or not. Perhaps the interpunction checking in usernames is too much or too complicated, so we can skip that for now. We could monitor if it becomes a problem, and add it to a later iteration if necessary. In most teams, it’s up to developers and testers to offer this for discussion, and for business representatives to decide on priority and scoping.
Even if the username interpunction examples for usernames end up out of scope, thinking about this them can lead you to consider similar boundaries for other input fields. Should we care about interpunction symbols in emails?
For example, Gmail allows users to put a dot anywhere in the email, or follow the email with a plus sign and a label, so “steve.o@gmail.com” and “steveo@gmail.com” are actually the same physical account, as well as “steveo+anything@gmail.com”. Popular email systems often have aliases, so “steve@gmail.com” is the same as “steve@googlemail.com”. How much do we care about preventing duplicated emails? Should we try to fight against commonly known cases such as that, or just ignore them? These are very specific domain questions, and the answers will depend on the risks you are trying to control. For a complex set of rules, there may be many more examples, and this table might become too big to read.
The next challenge
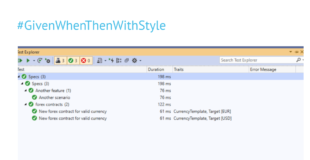
This brings us to the challenge. Let’s say that we actually do want to be a bit more strict about preventing the same person from registering twice, so all those Gmail hacks need to be handled. Plus the support managers came back and said that they liked the idea of avoiding problems with usernames that are too similar. This will lead to dozens, if not hundreds of examples. Alister also looks at examples around password complexity, which is another common aspect of registration that we might want to add to the registration feature. Putting it all into a single scenario outline is definitely not a good idea. How would you better structure such a big list of examples, so it’s easy to understand and maintain?
Solution on GitHub
We have also implemented the solution to this challenge with a simple SpecFlow example hosted on GitHub. Learn more about the sample code for challenges 1 and 2 in this blog post.
Solving: How to structure a long list of examples? #GivenWhenThenWithStyle
Last week, we cleaned up a vague scenario, transforming it into a relatively long list of concrete examples. The challenge for this week was to provide a good structure to capture all those examples in a feature file.
A large set of varied examples can be overwhelming. Examples that show important boundaries usually differ only in small details, so in a long list of examples many will contain similar information. Unfortunately, showing a lot of similar scenarios with only minor differences will make readers tune out and stop seeing the details, which is exactly the opposite of what we want to achieve with a good feature file.
Usually, a big part of the repetitive data comes from common preconditions. Developers often try to clean up such scenarios by applying programming design guidelines, such as DRY (“don’t repeat yourself”). They will remove all the duplication to achieve something akin to a normalised data set. This makes it easy to maintain and evolve the examples in the feature files, but it also makes it very difficult to understand individual scenarios. Readers have to remember too many things spread throughout a file to fully grasp the context of a single test case.
The key to capturing long lists of examples in a feature file is to find a good balance between clarity and completeness, between repeating contextual information and hiding it. Repeating the contextual information close to where it is used helps with understanding. On the other hand, repeating too many things too often makes it difficult to see the key differences (and makes it difficult to update the examples consistently). Here are four ways to restructure long lists of examples into something easy to understand and easy to maintain.
Identify groups of examples
For me, the first step when restructuring a long list of examples is usually to identify meaningful groups among them. Analyse common aspects to identify groups, then focus on clearly showing variation in each group.
Discovering meaningful groups of examples that have a lot of things in common allows us to just enough context to understand each group, allowing information to be duplicated across contexts, but focus examples in each group so they show differences between them clearly. There’s no hard rule how many examples should go into each group, but in my experience anywhere between three and 10 is fine. If a group contains more than ten examples, then we start having the initial problem again within that group, where readers start to tune out. Fewer than three examples usually gets me to ask if we covered enough boundaries to show a rule.
Each group should have a specific scope. On a very coarse level, groups can demonstrate a specific business rule. If there are too many examples to demonstrate a business rule fully, then structure groups around answering individual questions about that rule. If there are too many examples to fully answer a specific question, create groups around demonstrating a specific boundary or problem type.
Example mapping, a scoping technique for collaborative analysis promoted by Matt Wynne from the Cucumber team, turns this idea of groups of examples into a fully fledged facilitation technique. It starts by creating a breakdown of scope into topics, questions and groups of examples. If you start with example mapping, the map itself may provide good hints about grouping examples. You may still want to restructure individual groups if they end up too big.
Capture the variations
Within each group, try identifying the things that really change. Scenario outlines, mentioned in the previous post, are a nice way of dividing data from examples into two parts. One part will be common for the whole group, and you can specify it in the Given/When/Then section of the scenario outline. Another part of the data shows what’s really different between individual examples, and you can specify it within the Examples block, following the Given/When/Then.
As an illustration, when demonstrating rules around detecting duplicated emails during registration, we might want to show some more contextual information. To avoid potential bad assumptions about other types of errors (such as duplicated username), we might also want to show the proposed username and the name of the person registering. That information is not critical for each individual example, but it helps to understand the context. Instead of repeating it for each case, we can capture once for each group, in the When section.
Scenario Outline: duplicated emails should be prevented
Email is case insensitive. GMail is a very popular system so
many users will register with gmail emails. Sometimes they use
gmail aliases or labels.
To prevent users mistakenly registering for multiple accounts
the user repository should recognise common Gmail tricks.
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
When the Steve James tries to register with username steve123 and
Then the registration should fail with
Examples:
| email | registration message |
| mi.ke@gmail.com | Email already registered |
| mike+test@gmail.com | Email already registered |
| Mike@gmail.com | Email already registered |
| mike@Gmail.com | Email already registered |
| mike@googlemail.com | Email already registered |Notice that in this case the message is always the same, so there isn’t much point in repeating it. A table column that always has the same value is a good hint that it can be removed. A table column that only has two values in a group of 10 examples perhaps suggests that the group should be split into two sets of five examples.
We can move the values that are always the same to the common part of the scenario outline:
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
When the Steve James tries to register with username steve123 and
Then the registration should fail with "Email already registered"
Examples:
| email |
| mi.ke@gmail.com |
| mike+test@gmail.com |
| Mike@gmail.com |
| mike@Gmail.com |
| mike@googlemail.com |This set of examples is concise, but perhaps it’s too brief. It’s not clear why these examples need to be in the spec. With the earlier set of examples, the registration message helped to explain what’s going on. But the messages were the same for all these examples, so they were not pointing at differences between examples. We had to explain that in the scenario context, which is good, but can do even better. When there’s nothing obvious in the domain to serve that purpose, give each example a meaningful name. You can, for example, introduce a comment column that will be ignored by test automation:
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
When the Steve James tries to register with username steve123 and
Then the registration should fail with "Email already registered"
Examples:
| comment | email |
| google ignores dots in an email, so mi.ke is equal to mike | mi.ke@gmail.com |
| google allows setting labels by adding +label to an email | mike+test@gmail.com |
| emails should be case insensitive | Mike@gmail.com |
| domains should be case insensitive | mike@Gmail.com |
| googlemail is a equivalent alias for gmail | mike@googlemail.com | Identifying meaningful groups, and then structuring the examples into scenario outlines based on those groups, allows us to provide just enough context for understanding each group. It also allows us to use different structure for each set of examples. The scenario outlines around duplicated usernames will have different When and Then clauses (perhaps using a common email to show context). The examples themselves in that group would show variations in usernames. The When and Then steps will look similar to the ones we used previously, but likely use different placeholders from the examples that demonstrate email rules. The scenario outlines for password validity checks will have a totally different structure – perhaps not even showing the personal name and email.
Another useful trick to keep in mind with scenario outlines is that a single outline can have many example groups. If the list of examples around duplicated emails becomes too big, you can just split it into several groups. When doing this, I like to add a title to each group of examples, to show its scope. This allows us to ask further questions and identify further examples. For example, we only have two examples around case sensitivity. Thinking a bit harder about additional edge cases for that rule, we can start considering unicode problems. Unicode normalisation tricks can allow people to spoof data easily, abusing lowercase transformations in back-end components, and we might want to add a few examples to ensure this is taken care of.
Here is what an evolved scenario outline could look like:
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
When the Steve James tries to register with username steve123 and
Then the registration should fail with "Email already registered"
Examples: uppercase/lowercase aliases should be detected
| comment | email |
| emails should be case insensitive | Mike@yahoo.com |
| domains should be case insensitive | mike@Yahoo.com |
| unicode normalisation tricks should be detected | mᴵke@yahoo.com |
Examples: gmail aliases should be detected
| comment | email |
| google ignores dots in an email, so mi.ke is equal to mike | mi.ke@gmail.com |
| google allows setting labels by adding +label to an email | mike+test@gmail.com |
| googlemail is a equivalent alias for gmail | mike@googlemail.com |Use a framing example
As we start discussing more specific rules around preventing duplication, the structure of examples will change to reflect that. Each set of examples may have a different structure, focused on the key aspects that it is trying to show. That’s how you can avoid overly complex examples and tables with too much data. However, explaining a single feature through lots of different scenario outlines with varying structures might make things difficult to grasp at first. To make a feature file easy to understand, I like to use a framing scenario first. That scenario should be simple in terms of domain rules, and it should not try to explain difficult boundaries. It’s there to help readers understand the structure, not to prevent problems. A good choice is usually a “happy day” case that demonstrates the common flow by showing the full structure of data. For example, this could be the successful registration case. The framing scenario can then be followed by increasingly complex scenarios or scenario outlines. For example, I would first list the generic email rules, then follow that with system-specific rules such as the ones for GMail.
Feature: Preventing duplicated registrations
Scenario: Successful registration
...
Scenario: allowing duplicated personal names
...
Scenario outline: preventing duplicated emails
...
Scenario outline: preventing GMail aliases
...(Maybe) extract common preconditions into a background
With the framing scenario structure, you will sometimes find preconditions shared among all scenarios. In this case, the initial users in the repository might be the same for all examples. In cases such as that, you have an option to avoid duplication and move common preconditions from individual scenarios to a Background section. Automation tools will copy the steps from the background section before each individual scenario when they execute them.
When doing this, beware of hiding too much. The background section is useful only when the actual data is relatively simple so people can remember it. A common pitfall with using feature file backgrounds is that it becomes quite complex and readers lose the understanding of the feature before they even get to the interesting part. If you can’t keep the common background vert simple, it’s perhaps worth introducing just the minimum required inputs within each scenario outline itself.
Here is how a fully structured feature file, with a background section and a framing scenario, would look like:
Feature: Preventing duplicated registrations
To prevent users mistakenly registering for multiple accounts
the user repository should reject registrations matching
existing users
Background:
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
Scenario: Users with unique data should be able to register
When John Michaels attempts to register with the username "john" and email "johnm@gmail.com"
Then the user repository will contain the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
| john | John Michaels | johnm@gmail.com |
Scenario: Personal names do not have to be unique
When Mike Smith attempts to register with the username "john" and email "johnm@gmail.com"
Then the user repository will contain the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
| john | Mike Smith | johnm@gmail.com |
Scenario Outline: Usernames should be unique
Detecting simple duplication is not enough, since usernames that are visually
similar may lead to support problems and security issues. See
https://engineering.atspotify.com/2013/06/18/creative-usernames/ for more information.
When the Steve James tries to register with and "steve5@gmail.com"
Then the registration should fail with "Username taken"
And user repository should contain the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
| steve123 | Steve James | steve@yahoo.com |
Examples:
| comment | requested username |
| identical username | steve123 |
| minor spelling difference | Steve123 |
| unicode normalisation | sᴛᴇᴠᴇ123 |
| interpunction difference | steve123. |
Scenario Outline: Duplicated emails should be disallowed
Given a user repository with the following users:
| username | personal name | email |
| mike | Mike Smith | mike@gmail.com |
When the Steve James tries to register with username steve123 and
Then the registration should fail with "Email already registered"
Examples: uppercase/lowercase aliases should be detected
| comment | email |
| emails should be case insensitive | Mike@yahoo.com |
| domains should be case insensitive | mike@Yahoo.com |
| unicode normalisation tricks should be detected | mᴵke@yahoo.com |
Examples: Gmail aliases should be detected
GMail is a very popular system so many users will register
with gmail emails. Sometimes they use gmail aliases or labels,
to prevent users mistakenly registering for multiple accounts
the user repository should recognise common Gmail tricks.
| comment | email |
| google ignores dots in an email, so mi.ke is equal to mike | mi.ke@gmail.com |
| google allows setting labels by adding +label to an email | mike+test@gmail.com |
| googlemail is a equivalent alias for gmail | mike@googlemail.com |Solution on GitHub
We have also implemented the solution to this challenge with a simple SpecFlow example hosted on GitHub. Learn more about the sample code for challenges 1 and 2 in this blog post.
The next challenge
The challenge for this week is a bit more technical – dealing with situations that require waiting.
Stay up to date with all the tips and tricks and follow SpecFlow on Twitter or LinkedIn.
PS: … and don’t forget to share the challenge with your friends and team members by clicking on one of the social icons below 👇