The Right Way to Balance Clarity and Test Coverage
The next challenge deals with a common issue teams face when they seriously start using feature files as a repository of specifications and tests.
The tester in our team wants to add a lot of extra exceptions to Given-When-Then files, but from a specification perspective these just create confusion. What’s the right way to balance clarity and test coverage?
Here is the challenge
Examples are very useful for several purposes in a software development cycle:
- They can be used to facilitate a collaborative analysis session and create a shared understanding when a team is trying to decide what to build.
- They can be used to define a solid proportion of acceptance tests for an upcoming feature, or regression tests for existing features.
- They can also be used to clarify documentation and make it easy to understand what a feature is supposed to do, to support maintenance and future development.
Balancing all these different roles and purposes can be quite a challenge.
Here’s an example:
Scenario Outline: Users should be able to download videos
only when they have enough money to purchase them
Given a user account with balance of
When the owner wants to download a video costing
Then the transaction status should be
And the user account balance should be
Examples:
| balance | cost | status | new balance |
| 10 | 5 | approved | 5 |
| 5 | 6 | rejected | 6 |
| 10 | 10 | approved | 0 |Someone approaching this scenario outline purely from a documentation perspective might argue that even three examples are too much, and that one of the “approved” examples could be safely deleted without losing any meaning.
Someone approaching the same document from a shared understanding perspective might want to keep the 10/10 case just to prove that people didn’t wrongly interpret the boundary.
Someone approaching it from a testing perspective will likely want to add examples such as 9.99/10 or 10.01/10, as well as negative amounts, to ensure that there are no bugs in rounding or data storage.
Someone approaching from a test coverage perspective might want to add a range of costs for the same balance (for example, all amounts starting from 0.01 to 10.00 with a step of 0.01, such as 0.02, 0.03, 0.04 and so on). After all, once the basic automation is in place, it’s almost free to keep adding cases.
Someone approaching this from an exploratory testing perspective might want to mess around with data types or structure, passing non-numerical values, fractional values with different separators (comma instead of a dot), amounts with one or three decimals, very large or very small amounts, words instead of numbers, null or empty values and so on. With basic automation in place, exploratory testing becomes much faster so people can try many more values.
All those examples are perfectly valid, but for different purposes. Also, the more cases we add, the more difficult the list becomes to understand (and the slower the overall test feedback).
How would you structure this information to ensure a solid test coverage, at the same time keeping it easy to understand and provide fast feedback? How would you decide which of the cases are worth including, and which not?
Solving: How to deal with all the extra cases and exceptions?
This time, we’re solving the problem of stuffing Given-When-Then files with too many examples. Check out the original challenge for an explanation of the problem.
This post is an analysis of the community responses, and contains a few other ideas on choosing the right examples to keep in an executable specification.
When people complain about too many examples, they usually challenge some of the selected cases based on these aspects:
- redundancy: some examples might look as if they are effectively testing the same thing, so they add no real value
- relevance: some examples might not be important to test, at least not for the reader
- complexity: feature files with lots of examples tend to be difficult to read and understand
Seven types of coverage
Arguments about redundancy usually relate to test coverage. If many examples cover the same case, we probably don’t need to include all of them. However, we need to make sure the examples are actually covering the same case.
In the software testing jargon, this kind of analysis starts with ‘equivalence partitioning’, grouping inputs into buckets that lead to the same outcome. The idea behind partitioning is to build good test coverage with a relatively small set of cases. The problem with that idea is that it’s easy to approach it naively, and focus just on the different types of outcomes. The scenario outline from the initial challenge nicely demonstrates that problem. It tries to cover the two possible types of statuses, along with a third case that updates the balance in an interesting way.
Scenario Outline: Users should be able to download
videos only when they have enough money to purchase them
Given a user account with balance of
When the owner wants to download a video costing
Then the transaction status should be
And the user account balance should be
Examples:
| balance | cost | status | new balance |
| 10 | 5 | approved | 5 |
| 5 | 6 | rejected | 6 |
| 10 | 10 | approved | 0 |With a naive approach to coverage, these three might seem as the only examples that matter. Examples covering different classes of outputs are easy to think about, but they are rarely enough to ensure good testing. Lee Copeland, in A Practitioner’s Guide to Software Test Design, lists seven potential perspectives of test coverage:
- statements (lines of code)
- decisions (conditional execution branches)
- conditions (causes of selecting branches)
- combinations of conditions and decisions
- combinations of multiple conditions
- executing loops multiple times
- paths through the system
When discussing redundancy and relevance, it’s important to consider the perspective from which two cases might be equivalent or different. For example, the outcome in two cases might be the same (item #2 from the list), but it might have been selected for different reasons (item #3 from the list).
When doing collaborative analysis before development, the first item on the list (code lines) is difficult to argue about. But the second item (execution branches) is easy to imagine, at least from a business perspective. This is usually what product owners or business representatives contribute at the start of a specification workshop.
Counter-examples from the simple-counter-key technique (introduced in the solution to the first challenge) usually provide insight into item 3, pointing potential conditions that affect the selection of possible outcomes. Once we identify a good structure to document all the counter-examples, testers can usually provide ideas for items 4 and 5 in the list.
Items 1, 6 and 7 require a inside knowledge about how a feature is implemented, or will be implemented. This is where developers need to think about potential problems and also contribute examples. For example, if the tax calculation needs to be part of the feature under discussion, multiplying with fractional amounts might lead to a larger number of decimals, so we may need to consider rounding.
Don’t just discard groups because they test the same outcome. Consider different perspectives of coverage, and you might discover that the examples don’t belong to the same partition anyway. Instead of just deleting examples that seem redundant, it’s often better to address the cause of such redundancy.
Remodel to simplify partitions
By far, the most powerful option to reduce complexity and redundancy, while at the same time clarifying relevance, is to find implied concepts in examples and make them explicit in the model.
Most of the literature explaining equivalence partitioning or test coverage is approaching this problem from the perspective of testing after development, without being able to influence the cause of complexity. With specification by example, if done before development, we still have a chance to influence the design of the code. Fight complexity by remodelling, and simplify the partitions. This will reduce the number of test cases, but it will also make the system simpler, easier to develop, and easier to modify in the future.
For example, selling digital goods to EU residents often requires charging varying VAT rates, so someone with 10 EUR in the account might not be able to buy a video costing 10 EUR with tax added. We could have a bunch of examples relating to different countries and tax rates, with additional boundaries for rounding, or we could introduce the concept of tax-inclusive cost and simplify the whole thing. One part of the specification can deal with calculating the tax-inclusive cost and focus just on the rounding and tax rate configuration. Another feature could deal with deciding on transaction approval or rejections, given a calculated tax-inclusive cost.
Similarly, Rene Busch proposed introducing the idea of “standard currency fields” and formats, then specifying and testing those separately from the purchase process. This could encompass examples related to rounding, formatting and parsing values. The purchasing examples could then be significantly simpler, always starting from a valid currency amount. Developers from Europe or North America sometimes make wrong assumptions about currency rounding, assuming that two decimals are always the right choice. This led to mistakes costing hundreds of millions of dollars (check out my book Humans vs Computers for detailed examples). Modelling that part separately can significantly simplify the rest of the system.
Split validation from processing
Rene’s idea hints at a powerful technique that applies even if we do not remodel or introduce new concepts. One of the easiest ways to reduce the complexity of a feature file is to split validation from processing, mentioned already in the solution to the fifth challenge. There are many ways some entity can end up invalid, but invalid entities are usually processed in the same way (reject and send error).
Validation cases tend to have many boundaries around inputs, but often have very simple expected outputs (usually just the validation message). Processing cases tend to lead to different execution branches, and need to prove more complex output structures. Mixing the two types of test cases ends up in a combinatorial explosion of fields. Splitting them into two different feature files lets us keep both those files simple, because we can apply a different structure of examples in each of them.
Rejecting invalid currency formats or ensuring a valid rounded number are good illustrative cases for splitting validation and processing, but we can apply this technique much wider. In the purchase example, validation cases would probably include trying a transaction with nothing selected to purchase, or timing issues such as the requested video getting being blocked from sales after the user added it to the shopping cart. Depending on the business scope of the module we are trying to test, validation might also include purchasing videos without a declared sales price or with a negative price. All these cases could be handled separately, in a much simpler format, so that the main examples can remain clean and easy to understand.
Focus on the boundaries
If two cases lead to the same outcome, we do not need to document both of them. The 5/6 case and 10/10 case belong to the same partition from pretty much all perspectives, so we might not need one of them. But which should we keep?
From the perspective of test coverage, it may not matter which one we choose. But for shared understanding, it’s important to document where the meaning actually changes – the boundaries of the equivalence classes. Increasing the cost by 0.01 or reducing the balance by 0.01 doesn’t change much in the 5/6 case, but it may completely change the outcome in the 10/10 case.
Documenting boundaries and exploring adjacent cases is critical for effective specification by example, because individual assumptions might lead people to select different outcomes in the same situation. For example, consider the following case, which came up at a workshop I facilitated for a client a few years ago:
| balance | cost | status | new balance |
| 9.99 | 10 | ? | ? |The outcome seemed obvious to everyone, but it was different based on people’s job role. Developers and testers mostly selected the ‘rejected’ case, since there was obviously not enough money in the account. The salesperson selected the ‘approved’ case, since there was obviously enough money in the account. Exposing a difference in assumptions lead to clarifying what exactly ‘enough money’ means. The salesperson knew that 20-30% of their users abandon the purchase funnel when asked to enter credit card information, so they were balancing the 0.01 reduced profit against potentially losing one in four similar transactions. Developers and testers didn’t know that information, at least not until we discussed the example.
Cluster examples into scenario outlines based on importance
Several participants suggested clustering examples based on importance, or the intended audience. Creating logical groups makes it easier to understand patterns and allows different people to focus their attention on certain parts of feature files, and skip the ones that might not be relevant for them.
Lada Flac suggested grouping based on the type of checks, for example number format checks, boundaries check, data type checks and so on.
Fin Kingma proposed splitting the examples into three clusters:
I usually write scenarios with three different purposes:
1. Scenarios that focus on a business requirement. These usually don’t include examples to cover boundaries, but focus on making the most important business requirement clear. I’ve found that all user stories can be more clearly understood if you know the 1-3 most important business flows.
2. Certain PBI’s cause confusion on business requirements. I often add separate scenarios that focus on this confusion (because others might run into the same thing)
3. additional risks can be found in the application with certain combinations (you usually find them through exploratory testing, but they shouldn’t be translated 1:1 into BDD scenarios). Sometimes it’s useful to add a scenario to cover such a unique risky situation
Liam Harries and Rene Busch had almost identical proposals for grouping. The first group would contain examples illustrating the main business case, the second would look a bit deeper into examples around data formats and rounding, and the third group would contain various boundaries and additional test cases. David Evans used a similar approach, suggesting a guideline that you can use in a more general way:
I like to put a few key human readable examples first, and then provide more comprehensive cases in a table further down the feature file.
David published a sample feature file illustrating this approach, using the examples from the challenge.
Move purely technical examples to unit tests
Grouping examples in this way is great because people in different roles can easily focus on different parts of the feature file, so perceived redundancy is no longer a big problem. However, some examples might not really belong there at all. Jeroen Vis suggested moving extra examples to unit tests, keeping the testing pyramid in mind:
Remember the testing pyramid. I use specification by example only for acceptance tests. If there are extra tests needed for test coverage, then use unit tests. They are cheaper to implement and maintain. Only expand your acceptance tests if that is necessary to understand the scenario.
The testing pyramid usually applies to splitting user interface from service and unit tests, with higher-level tests integrating a larger piece of the system and running slower than lower-level focused tests. However, the speed of execution isn’t the key factor for coverage. When considering examples, particularly from the perspective of relevance, different test cases might be genuinely relevant at a different level.
For example, the user interface might not allow setting up an item with non-numerical cost, so business users might think that this case is not important to test. However, an API component may not want to trust the rest of the system to always provide prices in the correct format, so tests on the API level should explicitly check for formatting issues. This kind of structuring would translate nicely to Jeroen’s idea about the testing pyramid in a three-tier system, but with different types of architectures we need to generalise it. When considering which tests belong where, I tend to think about it more from the perspective of relevance than the testing pyramid. Particularly, what tests are relevant for what audience. Different examples will be relevant to different people.
Move examples that are relevant purely from a technical perspective into a developer-oriented tool. In most cases today, the right place for such examples would be a unit testing tool (not necessarily a pure unit test, but developers tend to use unit testing tools for a wide range of tests).
A good question to ask when deciding about keeping an example in a Given-When-Then feature file or moving it into a unit test would be “who would need to decide about fixing a failing test?” Imagine that you automated a test and it worked fine for six months, then failed one day. If the developers could decide on their own how to react, the example should go into a developer-oriented tool. If the failed test could be a bug or just reflected a change in business rules, then business users may need to comment on it, so it should go into a feature file.
Move exploratory/coverage examples into separate files
When introducing specification by example, and the tooling related to it, I often focus on the benefits around shared understanding and living documentation. Teams that focus too much on test automation tends to lose the value of collaborative analysis. However, that doesn’t mean that test automation does not have value on its own.
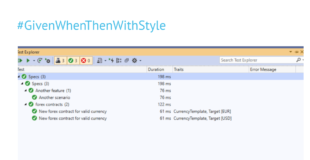
In particular, testers can use the initial few automated scenarios as a framework to explore the system quickly, and that can be a good use case for Given/When/Then tools. Just don’t mix up the examples intended for documentation with those intended for exploring the system. Many responses to this challenge proposed moving the additional examples to the bottom of a feature file, but I tend to completely move them out to different files.
Introduce a directory for exploratory work (I usually call this “sandbox”), and let testers go crazy there. They can copy and paste elements of feature files they’d like to explore, quickly change values and try out how the system works. Don’t include these files in your usual test runs and don’t generate documentation from them. This will let testers reuse automation to explore the system quickly, but it won’t unnecessarily prolong the main test suite execution, and it won’t overcomplicate documentation. When testers discover some important discrepancy through exploratory examples, you can discuss it as a group and perhaps add one or two examples to the main set to prove that the bug was fixed.
We can use the same approach for increasing test coverage for Copeland’s perspectives 4, 5 and 6. This usually requires many similar examples, which don’t add any value from a documentation perspective or for shared understanding. Testers might want to execute these test cases frequently, and if there is already automation in place for the relevant features, it would be a waste of time to manually run them. Again, a good solution to make everyone happy is to just separate those cases from the key specification examples. I often keep such examples in a separate directory, so it can be skipped when generating documentation from Given/When/Then files, but included in automated test runs. Keeping the two types of feature files in different directories also makes it easy to speed up feedback by running a smaller set first, then running the additional coverage examples only if the primary group passes.
Split examples into related groups
Applying all these tricks should significantly reduce the number of examples a single scenario needs to document. For cases when a scenario still has too many examples, and a single outline table would be difficult to understand, we might need to split it further. Some people prefer the scenario into several outlines and then copy/paste the introduction. There is a better option: you can introduce multiple groups of examples, each with a specific title and potentially even a contextual description. Just break up the Examples section into several tables.
As David Evans suggested, it’s often a good idea to start with a simple case. In the solution to the second challenge, we used a framing scenario to make the whole feature file easy to understand. We can use a similar trick with multiple groups of examples even in the same scenario outline. Start with the basic examples, perhaps even not the key boundaries, that just help readers understand the rest. Then start listing more and more complicated cases.
Scenario Outline: Purchase transactions should be approved
only when accounts have enough money
Note: the cost below is tax-inclusive, rounded to according to the
specification of the tax-calculation feature file.
Given a user account with balance of
And credit limit of 0.5
When the user wants to download a video costing
Then the transaction status should be
And the user account balance should be
Examples:
| balance | cost | status | new balance |
| 10 | 5 | approved | 5 |
| 5 | 6 | rejected | 6 |
Examples: to optimise the sales funnel, we should allow a small credit limit
| balance | cost | status | new balance |
| 10.00 | 10.01 | approved | -0.01 |
| 10.00 | 10.49 | approved | -0.49 |
| 10.00 | 10.50 | rejected | 10.00 |
| 0.01 | 0.5 | approved | -0.49 |
Examples: users already in the credit should not get additional credit
| balance | cost | status | new balance |
| 0 | 0.30 | rejected | 0 |
| -0.1 | 0.30 | rejected | 0 |Next Challenge
The next challenge in the Given-When-Then series is a common problem in situations when developing APIs or modules that connect to external systems.