BDD helps you find bugs before they find you. Learn BDD!
Behavior Driven Development creates a shared understanding of how an application should behave by discovering missing requirements based on concrete examples. This is how bugs & misunderstandings are prevented.
Shared understanding of requirements
Concrete examples of expected system behavior foster a shared understanding by being detailed enough for developers and testers while still making sense to business participants.
Developer
Tester
Product owner
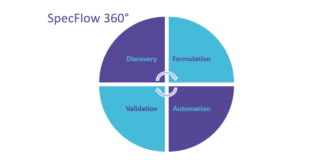
3 Phases of BDD Development
Discover
Formulate
Automate
1 Discover
Discovery refers to a structured, collaborative practice for specifying software requirements with examples. The process of Discovery is also known as a “Specification By Example workshop.” Discovery aims to overcome the blind spots of the “unknown-unknowns” in software development and reduce the learning bottleneck.
Developer
Tester
Focus on writing tests in natural language instead of building complex testing-code
Product owner
2 Formulate
Formulation is the practice of turning key examples from Discovery into formalized documentation, such as the easy to read Gherkin scenarios.
3 Automate
Automation is where formalized scenarios are turned into automated acceptance tests. Automated acceptance tests significantly reduce efforts for regression testing and provide immediate feedback when the specification documentation doesn’t match the system behavior anymore.
Developer
How does SpecFlow support BDD?
SpecFlow turns Gherkin scenarios into automated tests and helps teams bind automation to feature files and easily share the resulting examples.
Developer
Spend more time on coding feature-logic rather than debugging and explaining code.
What is the difference between BDD and TDD?
BDD pros and challenges
BDD pros
Collaboration
Allows for continued collaboration and increased visibility among the entire team.
User satisfaction
By focusing on the needs of the business, you get satisfied users — which translates to customer loyalty and better business outcomes.
Fewer bugs
Involving testers from the beginning means fewer bugs later.
Effectiveness
Since you extend the system in small increments, you can validate business values earlier and avoid unnecessary features. This prevents gold-plating and makes the overall implementation of the system more effective.
Faster feedback
Example scenarios describe focused, granular changes to the system under development. This enables teams to evolve the system in small steps while keeping it potentially shippable, allowing for shorter release cycles and faster feedback.
Code quality
BDD has a positive impact on code quality: it promotes emergent design that ensures loosely-coupled, highly cohesive architecture and avoids over-engineering.
BDD Challenges
Learning curve
As with any new methodology or practice that is introduced to new teams, there is a learning curve that requires the entire team to put time and effort into learning a new practice. Adopting a new practice may be a big challenge for some teams.
Initial time overhead
Creating and maintaining the feature files and scenarios requires an overhead investment of time and effort. In small projects, it may not be worth it, but in projects that have many iterations, you’ll definitely see a return on that investment.