How to fix dependancy chains in your scenarios.
This challenge is solving a problem I’ve often seen when manual tests get rewritten as Given-When-Then:
We have a long feature file. The scenarios build on each other, so the result of one scenario is effectively the starting point for another. This made it easy to write tests, but it’s making it difficult to maintain them. Someone updating a single scenario at the top of the file can break a lot of tests later in the file. How would you fix this?
Here is the challenge
When working with a system that has limited automation support, or performing actions that are very slow, it’s quite common (but unfortunate) to specify a feature through a chain of scenarios. Each scenario sets up the stage for the next one, expecting the context to continue from the preceding test executions. Some sections will even imply the “Given” part. For example:
Scenario: (1) register unique user
Given no users are already registered
When a user registers with username "mike99"
Then the registration succeeds
Scenario: (2) create order requires payment method
Given the user adds "Stories that stick" to the shopping cart
When the user checks out
Then the order is "pending" with message "Payment method required"
Scenario: (3) register payment method
Given user adds a payment method "Visa" with card number "4242424242424242"
When the user checks out the orders page
Then the order is "pending" with message "Processing payment"
Scenario: (4) check out with existing payment method
Given the user adds "Stories that stick" to the shopping cart
When the user checks out
Then the order is "pending" with message "Processing payment"
Scenario: (5) reject duplicated username
When a user registers with username "mike99"
Then the registration fails with "Duplicated username"There are three downsides of this type of structure.
The first is that the readers have to remember the context. For example, scenarios 2 and 4 have the same precondition and trigger, but a different outcome. In this particular case, as there is only one scenario between them, it’s relatively easy to guess why they are different. As the list grows, that becomes significantly more difficult.
The second is that updating scenarios becomes quite tricky. If, for some reason, we wanted to change the username in the first scenario, the last scenario also needs to change. Otherwise, the test based on that scenario will start to fail mysteriously.
The third is that problems in executing tests usually propagate down the chain. If a test based on the third scenario fails because of a bug, the fourth scenario test will likely fail as well, since the context is no longer correct. This can lead to misleading test reports and complicated troubleshooting. Verifying a fix also becomes more difficult, since it’s not possible to just execute the third scenario in isolation – we have to run the first two as well.
To fix the downsides, we also need to consider the reasons why people keep writing such specifications. Because each scenario extends the previous one, it’s quite easy to write the initial version of such a file. Also, as the steps from the previous scenarios do not need to be repeated to set up the context, the overall execution is quicker than if each scenario were to set up everything it needs from scratch.If you’d like to send a longer comment, perhaps write a blog post and then just send us the URL (you can do that using the same form, link below).
Solving: How to fix a chain of dependent scenarios?
The last challenge was to break up a chain of scenarios, each setting up the context for the next one. For a detailed explanation of the problem, check out the original post. This article contains an analysis of the community responses, and tips on more general approaches to solving similar problems.
There are many downsides to chaining scenarios, but that problematic way of writing endures because it also has two big benefits:
- It’s easy to convert manual tests into chained scenarios, because manual tests often use one test to set up the stage for the next one.
- The tests run faster than if each scenario had to be set up each independently (assuming all the tests pass), because the context gets initialised only once.
Several people suggested solving the challenge by including parts of previous scenarios directly into the later ones. This fixes the runtime dependency, so scenarios can execute independently, but does not really address the other underlying issues. It also loses the benefit of fast execution. To fully solve this problem, we’ll need to fix the downsides but keep the benefits. The big problem with rewriting manual tests into Given/When/Then is that they need to be optimised for human involvement in different ways.
Manual tests should be optimised for human involvement during execution. A person shouldn’t have to waste time setting up the same case over and over again just to try a slightly different variant. But a human can also adjust expectations during a test run. If scenario in a chain fails and leaves unexpected data in the system, a tester can easily adjust their expectations for tests that follow. A machine cannot.
Automated tests should be optimised for human involvement during troubleshooting. After the initial writing, humans mostly get involved with automated tests only when they fail or need to be changed. Chained scenarios make troubleshooting after failure difficult, since people have to analyse the whole sequence of execution to understand what went wrong. Modifying chained scenarios is also a lot more tricky than isolated ones, since someone can unintentionally break the context for many scenarios by updating something in the middle of the chain.
To avoid wasting time, people must be able to understand, modify and execute each scenario independently. Long test set-ups can be a problem, but we can deal with that in several ways once the tests are automated. A trivial solution would be to make each test independent, then run them in parallel on more hardware. However, there are better ways of speeding things up, but they depend on a different approach to writing scenarios.
Group related examples together
The first step in rewriting a long chain is usually to understand the dependencies between scenarios. Instead of using one scenario to set up the stage for another, we can identify groups of related scenarios, and then set up the context just once for each group. This can speed up execution significantly, but still keep each scenario relatively independent.
Jakub Nowak suggested moving the registration into the feature file background, deleting the first scenario altogether, and starting each scenario from the point of a system where the user needs to log in.
Background:
Given there's a user registered as 'mike99'
...
Scenario: (3) register payment method
Given User logs in as 'mike99'
And user adds a payment method "Visa" with card number "4242424242424242"
...The nice thing about this approach is that the background step automation can keep track of the user. It can add the user only on the first run, but skip it for subsequent scenarios and speed up execution. We could potentially even remove the username since it’s not that important for the three scenarios related to purchases, but the final scenario in the original post is preventing us from doing that. It needs a concrete username so it can check for duplication. This is a good hint that we should perhaps look for a different way of grouping examples.
Tom Roden suggested dividing the scenarios based on the business rule they are testing. In the example scenario from the original post, scenarios 1 and 5 test user registration. Scenarios 2, 3 and 4 deal with user check out. We can try restructuring the specification around those two groups.
If you can’t guess the business rules that scenarios are testing, then look for similar triggers (When steps). Grouping scenarios based on the action under test usually allows us to simplify set-up significantly, since scenarios in such groups usually need similar information. We can then have a concrete username for registration scenarios, and avoid specifying anything related to the user for purchase scenarios. Likewise, the contents of the shopping cart are irrelevant for registration scenarios, so we can avoid mentioning that.
One feature per file
In a response to the previous challenge, Faith Peterson suggested restructuring the feature specification into multiple files. The scenario in the previous challenge perhaps did not justify such a change, but this one surely does. We have two completely different topics here, and there is almost no benefit keeping them together – apart from saving some time on setting up the context.
People often mix up different features into a single file because they want to have a clear link between a work item (such as a user story) and the scenarios related to it. Having one feature file for each work item makes it convenient to decide when a user story is done, and to list all the changes or tests related to a user story. However, this approach has significant downsides in the long term.
Many user stories can affect a single feature over time. Spreading the knowledge over multiple files makes it difficult to reason about the current specification for that feature. It also makes it difficult to change all the related scenarios when a feature evolves. To make feature files easy to work with in the long term, I strongly suggest organising files around features, not stories. Do not keep more than one topic in a single file, since they will likely evolve independently.
Knowing which scenarios are related to an individual story is sometimes important, but there are better ways of doing that. A common workaround is to use tags on scenarios or features to relate them to work items. For example, to show that a scenario relates to story 1912 in JIRA, we could mark the scenario in the following way:
@JRA-1912
Scenario: Order checkout Tags are available in most Given/When/Then tools. Specflow, in particular, also has convenient support for linking directly to items in Azure DevOps.
Write set-up in a declarative way
Instead of just splitting scenarios into multiple files, we should also rewrite them to make more sense. Although I like to avoid comparing Given/When/Then to programming languages, one area where this relationship does make sense is contrasting declarative with imperative style.
Broadly speaking, there are two types of programming languages. Imperative languages (such as Java, C# or JavaScript) define an algorithm using a sequence of actions that a computer should perform. They define the implementation. Declarative languages (such as Prolog or most SQL) define the intention of work without specifying the flow of actions. Declarative code is more limited than imperative in terms of the actions it can perform (Prolog can only perform logic deductions, SQL can only manipulate tabular data). On the other hand, for the limited domains where it works, declarative code is often easier to understand, modify and execute. These are exactly the benefits we want from the scenarios.
Declarative code leaves the implementation of the algorithm to the language interpreter or compiler, so all sorts of wonderful optimisations can be applied in a context-specific way. The same SQL query can run completely differently on a small table of 10 records or on a gigantic table consisting of millions of records on different shards with multiple indexes. The person writing the SQL query usually doesnât need to care about that. Similarly, someone writing a feature specification shouldn’t need to care about how a test runs.
As much as possible, aim to define scenarios in a declarative way. This is particularly important for preconditions (Given) and postconditions (Then). Declarative statements are usually shorter than imperative ones, and such scenarios will be easier to understand and modify. Imperative steps constrain automation to follow a very specific flow, so people automating the tests cannot optimise it much. Declarative steps allow developers to optimise test execution in context-specific ways. For example, instead of a user being registered through the web app, test automation can just insert a user record directly into the database. This can speed up testing significantly.
In the context of executable specifications, the difference between imperative and declarative is often explained as how vs what. Scenarios should describe what the system should do, instead of explaining how a test is executed. One good trick for that is to avoid active verbs in Given and Then sections. Don’t specify the setup with a user doing something, such as:
Given the user adds "Stories that stick" to the shopping cartInstead, explain the state of the system. Victor Cosqui suggested these declarative ways of defining the scenarios:
Scenario: (3) register payment method
Given an order done and pending to add a payment method
...
Scenario: (4) check out with existing payment method
Given an order done and it has payment method
...Setting up the scenarios in a declarative way lets us reduce the clutter and focus on things that are actually important in each scenario group. We can then spot commonalities and variations between examples, and remove duplication easily.
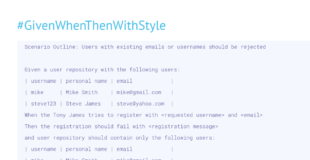
Extract scenario outlines
As part of the first challenge, I suggested restructuring a group of similar scenarios into a scenario outline. We can do the same in this case.
The first group, related to preventing duplicate registration, will end up very similar to the solution to the first challenge.
The second group, dealing with the cart check-outs, seems to revolve around a shopping cart being set up with some items, and the payment method being registered or not registered. Thereâs not need to repeat the whole flow each time, we can extract a common structure, such as the one below:
Given a user with payment method
When the user checks out a shopping cart
Then the order status should be
And the order display message should be
Examples:
| payment method status | order status | order message |
| no | pending | payment method required |
| registered | pending | processing payment |At this point, we can also rephrase scenario titles. Most scenario titles in the original example seem to imply the test set-up or the action under test. They don’t provide the scope for the test. Tom Roden wrote:
One way I find useful for sense checking scenarios quickly, read them backwards and then read the title — is the outcome validating the title? Also is the title specific enough to describe the rule without having to read all the examples (oh, and are the examples even remotely connected to the title).
By creating scenario outlines around groups, we get a chance to create more meaningful titles that would relate to the business rules, not just a fragment. Tom suggested the following title:
Scenario: Order needs a valid payment method to be processed Explore boundaries
A scenario outline with a few examples is a great start for the conversation. To check if this is actually what we should be doing, use the Simple-Counter-Boundary technique. These two initial examples are the simple ones. Next we need to try identifying counter examples which could violate one of the illustrated rules.
For start, be very suspicious about a table column that has only one value. If the order status is always going to be pending, it’s better to move it to the scenario outline above the table of examples. But first, can we think of some counter-example that could violate this rule? How about an empty shopping cart? We probably don’t want to submit the order to payment, but instead show a different message.
Considering this topic opens up a different structure. We perhaps need to look at the number of items in the cart.
Examples:
| payment method status | number of items | order status | order message |
| no | 0 | invalid | empty cart |
| no | 1 | pending | payment method required |
| registered | 0 | invalid | empty cart |
| registered | 1 | pending | processing payment |The last step would be to look at additional boundaries using this structure. For example, could some payment method status cause a further complication? Tom Roden suggested two examples that could be problematic: expired and inactive. Perhaps we should not be submitting expired payment cards to payment.
| expired | 1 | ???? | payment method expired |
| inactive | 1 | ???? | ???? |Regarding inactive methods, thatâs an interesting question that needs to be answered in a business-specific way. For example, sometimes customers submit a chargeback request not recognising an order, or a credit card processor can flag some card numbers as potentially stolen or fraudulent. We might decide to deactivate such payment methods until we get a resolution for the problems. Business stakeholders might decide to temporarily suspend the customer account and not let them order any more, or allow orders but require a different payment method.
Lastly, the number of items being 1 or 0 doesn’t mean much unless there are some other specific constraints. This is where asking an extreme question helps. Check if an order with 100000 items should just go directly to payment processing or not. If business representatives start scratching their heads, there’s probably some upper limit that would require an additional risk validation. If not, we should probably remove the number and rephrase this somehow differently.
We could also go in the other direction. How about an order with -1 items? Before you dismiss this as a silly situation that could never happen, you should know that one of the largest online retailers ran into that problem, and lost money on it. (For the full story check out the “-1 books” chapter in my book Humans vs Computers). Some systems allow returns as “negative order” and need to process a refund in such cases. Some systems should politely just refuse this. Either way, it doesn’t hurt to discuss it.
Split validation and processing
Even if we decide to flatly reject negative orders, same as the empty ones, this structure still leaves us with quite a few things to try out in the scenario. Why stop at 0 and 1 items? Should we test 2, 3, 4 and so on? This is where testers and developers usually disagree. Developers will often argue that those scenarios should all have the same outcome, so testing a single one is enough. Testers focus more on the difference between should and does, so they may want to check various scenarios to ensure the expectations match reality.
A good way to resolve this, so that both groups are happy but still prevent overcomplicating scenarios, is to split validation and processing. There are plenty of ways something such as a shopping cart can be invalid, but we can define that separately from handing a valid cart. Splitting the examples that make something valid or invalid from the examples that show how to process a valid entity is usually a good way to avoid a Cartesian product of boundaries.
Feature: Order checkout
@JRA-1912
Scenario: Order checkout depending on payment method
Given a user with payment method
When the user checks out a valid shopping cart
Then the order status should be "pending"
And the order display message should be
Examples:
| payment method status | order message |
| no | payment method required |
| valid and current | processing payment |
| expired | payment method expired |
| inactive | ??? |
@JRA-1912
Scenario: shopping cart status based on items
Given a user with in the cart
And the risk treshold for orders is 1000
When the user tries to checks out
Then the shopping cart status should be
Examples:
| number of items | status |
| -1 | invalid |
| 0 | invalid |
| 1 | valid |
| 999 | valid |
| 1000 | valid |
| 1001 | invalid |
| 1000000 | invalid |Introducing validity into the model also makes it explicit why developers expected cases with 2, 3, 4 items to work the same. By modelling it in, we can structure the system so it’s easy to reason about it. This also makes the system easier to evolve in the future. This structure allows us to extend the concept of cart validity with other categories, such as items being out of stock, or breaking down quantities into groups of individual item types (for example, someone could try ordering 10 copies of one book, and -6 copies of another). This would not require changing the “Order checkout depending on payment method” scenario.
Beware of simple fixes
Similarly to the previous challenges, this one was easy to fix on the surface. We could just copy set-up steps into each scenario and break up the chains. However, restructuring into groups and exploring boundaries allows us to discuss aspects of a system that would have been overlooked. This in turns allows people to design a better solution and avoid tricky problems. Beware of simple surface fixes for scenario chains, and use the opportunity to go deeper when restructuring such files. It will pay off big.