How to specify hierarchical data?
Given-When-Then examples work nicely with structured data, particularly if it can fit well into tables. Things become tricky with data that has more than two levels of hierarchy. For example, a scenario might involve several users, each with several addresses and accounts, and transactions within each account. This does not fit neatly into a single table. The challenge for this week is describing those kinds of hierarchies in Gherkin.
Below are a few common options for you to choose, based on what I’ve seen in the wild. This challenge is probably more open-ended than the previous ones, since there are many other ways to solve the same problem. If you know of a better way, please post your solution somewhere and send us the link.
Here is the challenge
Option 1: chain together individual entities
The first way of specifying hierarchical data is to start at a higher level for the context (in this case “user”), and use it to provide context for the following statements, implicitly specifying the hierarchy:
Given user Leto
With the following addresses
| type | street address | city |
| home | Central Plaza 1 | Caladan |
| office | Grand Palace | Arrakeen |
And the following account
| type | currency | balance | status |
| current | USD | 100 | active |
And the following transactions in account
| date | amount | description |
| 2 January | 2000 | flight ticket |
| 3 January | 1500 | desert suit |
And the following account
| type | currency | balance | status |
| credit | USD | -400 | active |
And the following transactions in the account
| date | amount | description |
| 1 January | 5000 | spice |
| 2 January | 7500 | spice |
| 4 January | 5500 | spice |
Given user Vladimir
With the following addresses
| type | street address | city |
| office | Shield Wall Street | Carthag |
...Option 2: relational table normalisation
Alternatively, instead of chaining entities to provide context, we could introduce identifiers and just represent the hierarchy as flat tables, similar to a relational database.
Given the following users:
| userid | name |
| UID_1 | Leto |
| UID_2 | Vladimir |
And the following addresses:
| userid | type | street address | city |
| UID-1 | home | Central Plaza 1 | Caladan |
| UID-1 | office | Grand Palace | Arrakeen |
| UID-2 | office | Shield Wall Street | Carthag |
| UID-2 | home | Star Jewel 2 | Giedi Prime |
And the following accounts:
| accountid | userid | type | currency | balance | status |
| AID_1 | UID-1 | current | USD | 100 | active |
| AID_2 | UID-1 | credit | USD | -400 | active |
| AID_3 | UID-2 | credit | RUB | -400000 | active |
And the following transactions:
| accountid | date | amount | description |
| AID_1 | 2 January | 2000 | flight ticket |
| AID_1 | 3 January | 1500 | desert suit |
| AID_2 | 1 January | 5000 | spice |
| AID_2 | 2 January | 7500 | spice |
| AID_2 | 4 January | 5500 | spice |
...Option 3: embed hierarchy as text
Gherkin does not have a good way to embed tables into tables, but it does support free-form text enclosed in three quotes. We could use a hierarchical text format (such as YAML, JSON, or even just simple indentation) and then parse the string into a hierarchy of objects in the step implementation. This would allow us to specify the entire user hierarchy in a visual way, at the expense of more complex parsing.
Given the user
"""
name: Leto
addresses:
- type: home
street: Central Plaza 1
city: Caladan
- type: office
street: Grand Palance
city: Arakeen
accounts:
- type: current
currency: USD
balance: 100
status: active
transactions:
- date: 2 January
amount: 2000
description: flight ticket
- date: 3 January
amount: 1500
description: desert suit
- type: credit
currency: USD
balance: -100
status: active
transactions:
- date: 2 January
amount: 75000
description: spice
- date: 3 January
amount: 5500
description: spice
"""
And the user
"""
name: Vladimir
addresses:
- type: home
street: Star Jewel 2
city: Giedy Prime
"""
...
Option 4: use data in external files
Instead of embedding all that hierarchical data, we could also move it to an external file, and provide just the file name to the automation step:
Given the user Leto with data from users/leto_a.txt
And the user Vladimir with data from users/vladimir_h.txtSolving: How to specify hierarchical data?
Last time, you voted for options on specifying hierarchies of entities with Given-When-Then. There was no clear winner in the votes, which perhaps isn’t surprising as there are just no perfect solutions to that problem.
Visualizing hierarchies usually requires recursive structure formatting and often involves graphical notation or strict indentation, none of which is possible with Given-When-Then. However, there are some potentially good workarounds for this problem in different contexts.
When in doubt, optimize for reading
An important guideline for Given-When-Then scenarios is that they need to be easy to understand. If it takes a long time to figure out what’s going on, people will not be able to discuss expected outcomes easily or distinguish between bugs and outdated tests in the future. I suggest always optimizing a scenario for reading, and dealing with the rest in the automation layer (step implementations).
Very often, when I’ve seen data hierarchies specified in real projects, they were driven by one of the following two needs:
- the same data set is used to demonstrate lots of different scenarios (usually in reporting systems)
- a scenario wants to show some behavior related to several different groups of entities, such as showing aggregation across different accounts
There are good workarounds for both situations that do not require listing the whole hierarchy of records.
Focus on one scenario at a time
When a data set is used to demonstrate lots of different scenarios, a business domain expert usually prepares a “golden data source” that can demonstrate a whole range of features, which almost always maps to database tables.
This approach optimizes writing the scenarios but makes it very difficult to understand failures, and becomes very tricky to maintain. Over time, this set of scenarios becomes cement that prevents code from changing. Any modification that requires an additional record usually breaks hundreds of unrelated tests and puts people off from changing the pristine data. Scenarios become more and more convoluted as they try to reuse existing data, that was set up for a different purpose.
It’s far better to break up the test configuration so that each scenario prepares only what it needs, and so that individual scenarios can focus on whatever level of the hierarchy is important for them.
Sometimes the “golden data source” approach makes execution faster, as the automation system can prepare data only once before all tests. We can start from a well-known state, and individual scenarios can only add the extra bits that they need. Listing the hierarchy inside Given-When-Then is not necessary in this case. We can use an external file with a technical structure to set up the scenarios, or even a binary database file that can be easily restored. Scenarios can modify this only by tweaking individual records that are truly important for them.
An important trick to use in such cases is to quickly bring back the clean state before each test. I suggest running tests inside database transactions. After each scenario, automatically roll back the transaction to cancel any pending changes, and restore the database to the well-known state.
Show aggregate properties only
When a scenario shows some behavior related to groups of entities, it’s usually possible to avoid listing the entire hierarchy by just focusing on the aggregate properties. The automation layer can use that information to create the appropriate data. For example, if we wanted to demonstrate that individual users can only access their own transactions, it doesn’t matter so much what the individual amounts are. We could prepare the scenario like this:
Given 2 users with credit and current accounts
And each account has 3 transactions from 1 January to 3 January and amounts between 101 and 103
...
When user-1 requests a "credit" account listing
Then the following transactions are reported
| account | amount | date |
| user-1-credit | 101 | 1 January |
| user-1-credit | 102 | 2 January |
| user-1-credit | 103 | 3 January | The second step implementation can just fill in the blanks and automatically create the appropriate accounts and transactions. Note that in this case, I’m also specifying the date and amount ranges. We could also infer those and make the scenarios simpler, but sometimes it’s good to be able to control the variation.
Specify target properties more directly
When a scenario cares about individual records, it’s rare that it needs to be specific about all levels of the hierarchy at the same time. Usually, a scenario focuses on one concept to explain how it works. In such cases, it’s better to specify that level of hierarchy directly, and infer the other levels in the automation to just fill in the blanks.
For example, if we really care care about the transactions, we could collapse the user and account and present the key properties with the transaction amounts, such as in the table below:
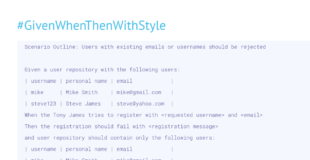
Given the following transactions:
| owner | account type | date | amount |
| leto | credit | 2 January | 2000 USD |
| leto | credit | 3 January | 500 USD |
| leto | current | 3 January | 1500 USD |
| vladimir | credit | 2 January | 5000 RUB |This can lead to some redundancy, but if only a small number of items are relevant, this is usually a good compromise.
Denormalising data in this way helps with reading, but it makes it possible to introduce inconsistencies. For example, because we’re not separately specifying accounts with currency configuration, someone could easily add transactions for two different currencies into the same account. However, we can protect against that in the automation layer, preventing inconsistent entries. This approach makes test automation slightly more complicated but helps with reading and understanding. I think this is a good trade-off.
What if we really want the whole hierarchy?
Assuming that none of the mentioned workarounds make sense, and that for a specific scenario we actually want to list the whole hierarchy, my preference would be option 1 from the original challenge (chain together individual entities). Each level provides the context for reading the next one, which makes it easy to understand what’s going on. It also makes it easy to modify any piece of information. As before, this approach makes automation more complex but makes it easier to read scenarios.
With option 2 (normalized tables), adding a transaction might require modifying things in the accounts table, and this is difficult to track for humans (that’s why we have RDBMS systems). SQL normalization is optimized for storage and CPU processing, not for reading. Even when the information is inside a relational database, people rarely consume it directly by listing full tables. We usually produce queries or views that make the contents more accessible. Ken Pugh proposed an interesting alternative that visualizes a hierarchy almost like a hierarchical view of relational data, fitting into the syntax of Gherkin pipe-separated tables. Check out his example for more information on it.
With option 3 (embedding hierarchy as text), the contents usually have a special structure that either ends up too technical or too brittle. For example, the YAML format from the original example puts special meaning on leading white space in each line. Slightly messing with that can change the meaning of the hierarchy in unexpected ways. Inserting the wrong number of spaces, or using a tab instead of a space can make a transaction an orphan or assign it to the wrong account, and that will be difficult to spot in the scenario description when shown on the screen. Gherkin editors do not place so much importance on white-space, and mixing Given-When-Then with a format where indentation is critical makes it very error-prone. The alternative is to use a format that implies structure in some other way, such as XML or JSON, but then the scenario itself becomes cluttered with formatting marks and difficult to read.